The Most Comprehensive Video Dataset Sharing: Part 2, VideoQA Datasets
In the digital era, artificial intelligence has permeated various fields, becoming a pivotal force driving technological innovation and societal development. From early rule-based simple algorithms to the current complex intelligent systems represented by deep learning, every major breakthrough in artificial intelligence has been closely linked to the exponential growth of data and leaps in processing capabilities. Video data, as an information-dense and visually intuitive data source, plays a crucial role in this evolutionary process. With the massive generation and widespread application of video data, video understanding technology has become increasingly important. It enables automatic classification, annotation, and retrieval of video content, enhancing the efficiency and accuracy of video processing, and providing robust support for various applications such as video surveillance, intelligent transportation, film production, and online education.
Video datasets provide large models with rich spatiotemporal information, enabling them to learn dynamic features such as object motion, scene changes, and event progression. High-quality video datasets encompass diverse scenes, actions, and contexts, which help improve the generalization capabilities of models, making them more robust when facing the complexities of the real world. In emerging tasks such as text-to-video generation, comprehensive and diverse video datasets are indispensable, as they provide models with the knowledge to map from text to visual sequences.
Overview of VideoQA Datasets
VideoQA datasets are meticulously constructed multimodal data resources that organically integrate video clips with related textual questions and answers. A typical videoQA dataset primarily consists of the following key components:
- Video Clips: These videos cover a wide range of domains and scenarios, including but not limited to daily life recordings, movie clips, news reports, educational lectures, and sports events. The duration, resolution, frame rate, and other parameters of the videos vary depending on the design purpose and application scenario of the dataset. For example, in research focused on short video understanding, video clips may be only a few seconds long with relatively low resolution to simulate the common format of short videos on social media platforms. In datasets designed for movie plot analysis, video clips may be longer and of higher quality to capture complex plots and details.
- Question Texts: The questions related to the videos are designed to test the machine's various understanding capabilities of the video content, such as object recognition, action recognition, event reasoning, emotion analysis, and semantic understanding. The questions come in a rich variety of forms, ranging from simple factual inquiries (e.g., "How many apples appear in the video?") to complex reasoning questions (e.g., "If the protagonist had not chosen this path, how would the plot have developed?"). The linguistic expressions of the questions also exhibit diversity, including various sentence structures and grammatical forms in natural language, which places high demands on the model's language comprehension abilities.
- Answer Texts: For each question, one or more accurate answers are provided. The format of the answers depends on the type of question and may include short textual descriptions (e.g., "Three apples"), annotations of specific time points or intervals in the video (e.g., "From 10 seconds to 20 seconds in the video"), or even complex logical reasoning results (e.g., "The protagonist might encounter another character, leading to a new conflict").
The Key Role of VideoQA Datasets in Training Generative AI Models
The Learning Foundation of Multimodal Information Fusion
Generative AI models aim to generate coherent, reasonable, and contextually relevant responses based on input information. For videoQA tasks, the model needs to simultaneously process visual information from the video and textual information from the question, effectively fusing the two. videoQA datasets provide the model with a large number of multimodal samples, enabling it to learn the mapping relationships between visual features and textual features. By learning from numerous video clips and question-answer pairs in the dataset, the model gradually masters how to extract key information from visual elements such as scenes, colors, and actions in the video, and combines this with the semantic information in the question to generate accurate answers. For example, in a videoQA dataset focused on animal behavior, the model, through repeated learning of animal movements, postures, and corresponding questions and answers in the videos, can learn to recognize behavioral patterns of different animals and accurately describe what an animal is doing or might do next based on the question.
Cultivation of Semantic Understanding and Reasoning Abilities
The rich and diverse types of questions in the dataset drive generative AI models to continuously improve their semantic understanding and reasoning capabilities. From simple fact-based questions to complex causal relationships, logical reasoning, and emotion analysis questions, the model gradually masters the semantic structures and logical rules of language during the learning process. For example, in a dataset containing questions about character emotion analysis, the model learns to infer emotional states such as happiness, sadness, or anger by analyzing characters' facial expressions, movements, language, and contextual information in the video, combined with the emotional inquiries in the questions. The cultivation of such reasoning abilities not only helps in answering complex questions in videoQA tasks but also transfers to other natural language processing tasks, enhancing the model's general intelligence level.
Optimization of Language Generation Capabilities
When answering videoQA tasks, generative AI models need to generate clear, accurate, and grammatically and semantically compliant textual answers. videoQA datasets provide the model with abundant language generation training materials. By learning from a large number of questions and answers, the model can master the response patterns and linguistic expressions for different types of questions, improving the fluency and accuracy of language generation. Additionally, the diversity of answers in the dataset encourages the model to flexibly generate appropriate responses based on different video content and question contexts, avoiding overly monotonous and formulaic answers, thereby enhancing the quality and practicality of the model's responses.
VideoQA Datasets
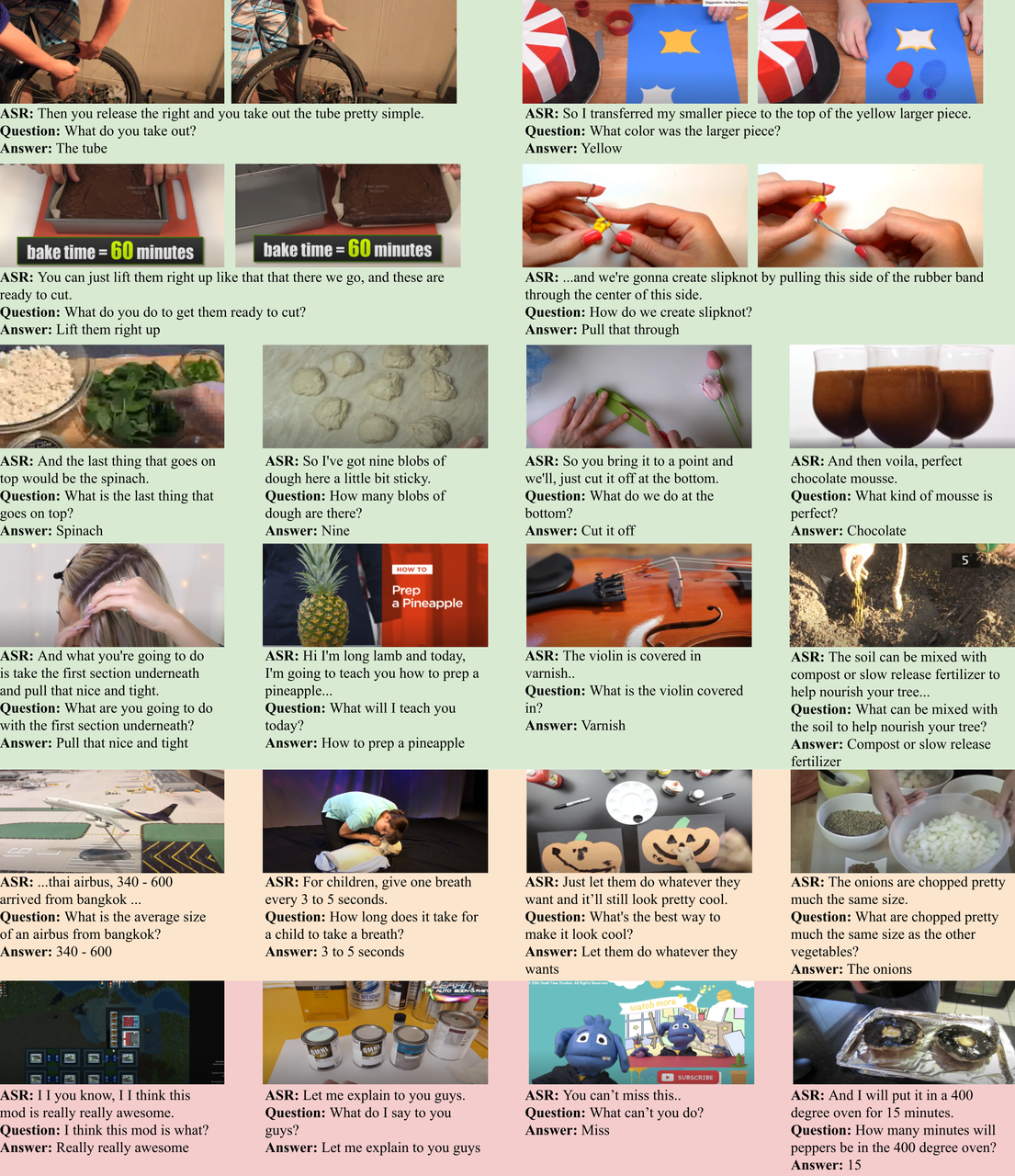
MSRVTT-QA
- Publishing Team: Microsoft Research
- Release Year: 2016
- Download Link: https://github.com/xudejing/video-question-answering
- Dataset Size: Contains approximately 10,000 video clips, with each video accompanied by about 20 question-answer pairs, totaling around 200,000 question-answer instances.
- Dataset Description: This dataset is built upon the MSR-Video-to-Text (MSRVTT) dataset, with video content covering various domains such as daily life scenes, sports, and news. The questions primarily focus on characters, objects, actions, and events in the videos, making it an early and representative dataset in the field of videoQA research. The videos in the dataset are relatively short, averaging around 10-20 seconds, which allows models to focus more on extracting and understanding key information when processing concise video content. This facilitates research on short videoQA techniques and the model's reasoning and answering capabilities under limited information.
TGIF-QA
- Publishing Team: Columbia University
- Release Year: 2018
- Download Link: https://github.com/YunseokJANG/tgif-qa
- Dataset Size: Contains approximately 165,000 video question-answer pairs, with videos sourced from the TGIF (Tumblr GIF) dataset.
- Dataset Description: The TGIF-QA dataset primarily consists of a large number of short videos in animated GIF format, featuring unique visual styles and content characteristics. It focuses on short videos (primarily GIFs), with question types including action recognition and object localization. Due to the short length and typically simple, intuitive content of the videos, this dataset is highly useful for studying models' rapid understanding and answering capabilities in simple visual scenarios. It also provides suitable training data for developing lightweight and efficient videoQA models, particularly for resource-constrained applications such as videoQA on mobile devices.

MovieQA
- Publishing Team: University of Southern California
- Release Year: 2016
- Download Link: http://movieqa.cs.toronto.edu/
- Description: The MovieQA dataset contains approximately 14,000 questions related to 408 movies, covering various film genres including drama, comedy, action, science fiction, and more, offering a rich diversity of movie themes and styles. The MovieQA dataset is based on movie content, with questions focusing on movie plots, character relationships, scene details, and other aspects. It provides abundant material for videoQA in the film domain, facilitating research on generative AI models related to movie understanding.

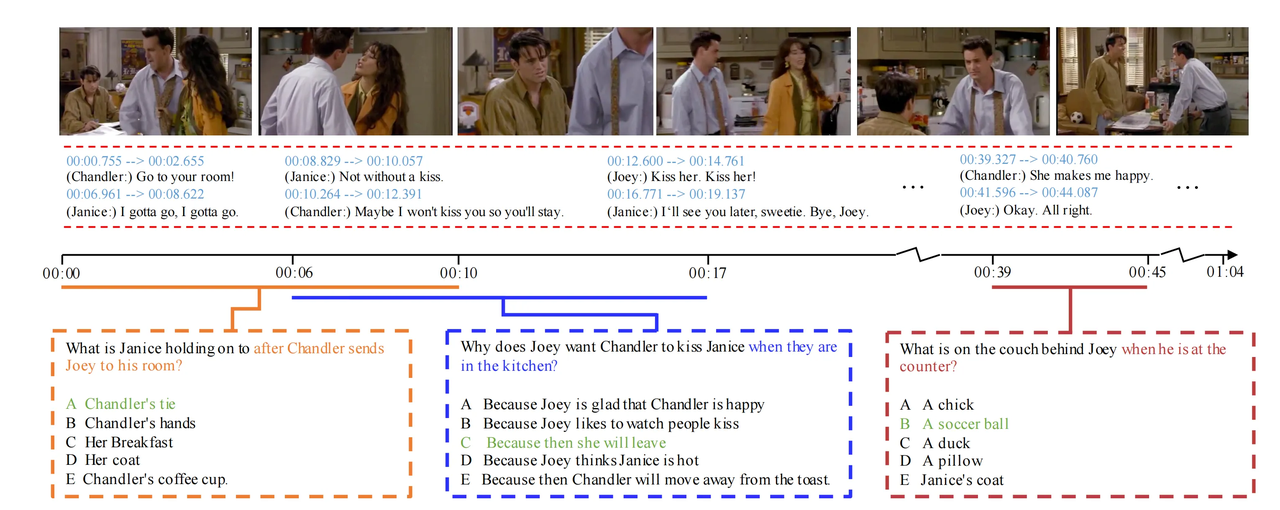
TVQA
- Publishing Team: Georgia Institute of Technology
- Release Year: 2019
- Download Link: https://github.com/jayleicn/TVQA
- Description: TVQA contains over 21,000 questions, with corresponding videos sourced from 6 popular TV shows, covering various genres such as sitcoms, mystery, historical drama, and science fiction, featuring coherent storylines and rich character relationships. The questions encompass aspects such as TV show plots, character emotions, and dialogue meanings. Given that TV shows have long narrative arcs and complex character interactions, this dataset is highly valuable for studying the capabilities of generative AI models in long-term plot understanding and question answering. For example, in smart TV interaction systems, users can ask questions about the TV show they are watching at any time, and the model can provide accurate answers based on the plot context, enhancing the viewing experience. Additionally, it offers data support for research on TV show plot analysis and audience feedback prediction.
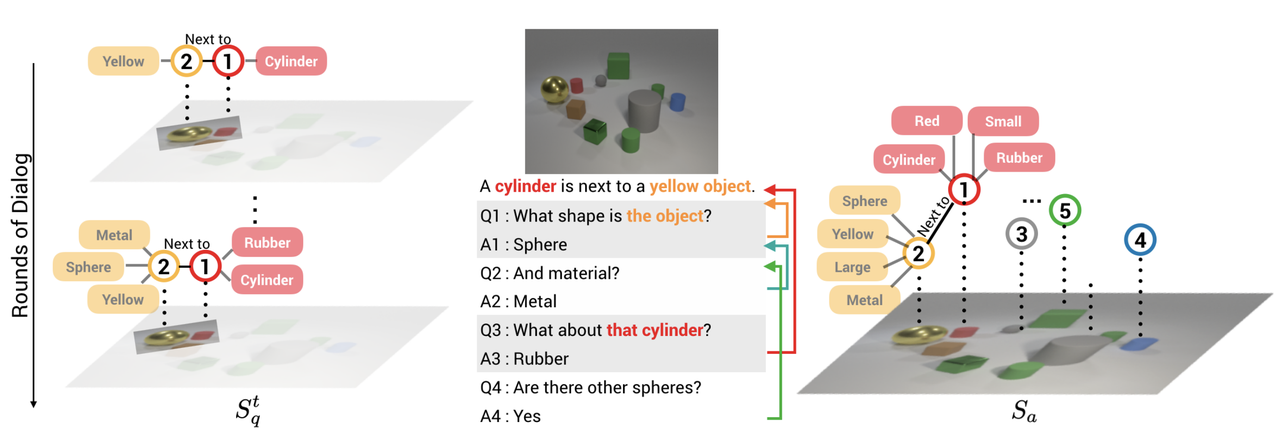
CLEVR-Dialog(Video-based)
- Publishing Team: Facebook AI Research
- Release Year: 2019
- Download Link: https://github.com/satwikkottur/clevr-dialog
- Description: The CLEVR-Dialog (Video-based) dataset uses synthetic videos, where objects and scenes are programmatically generated, offering high controllability and repeatability. This facilitates in-depth research by allowing researchers to focus on specific visual elements and question types. The dataset is primarily used to study the reasoning capabilities of models and their performance in answering questions about synthetic videos. The questions mainly involve logical reasoning and relationships between visual elements, such as spatial reasoning, attribute reasoning, and event reasoning. By training on this dataset, models can learn precise reasoning rules and logical relationships in a controlled environment, which is significant for enhancing their reasoning abilities and performance in complex visual reasoning tasks. It also provides strong support for developing generative AI models with robust reasoning capabilities, with potential applications in fields such as virtual reality and intelligent game interactions.
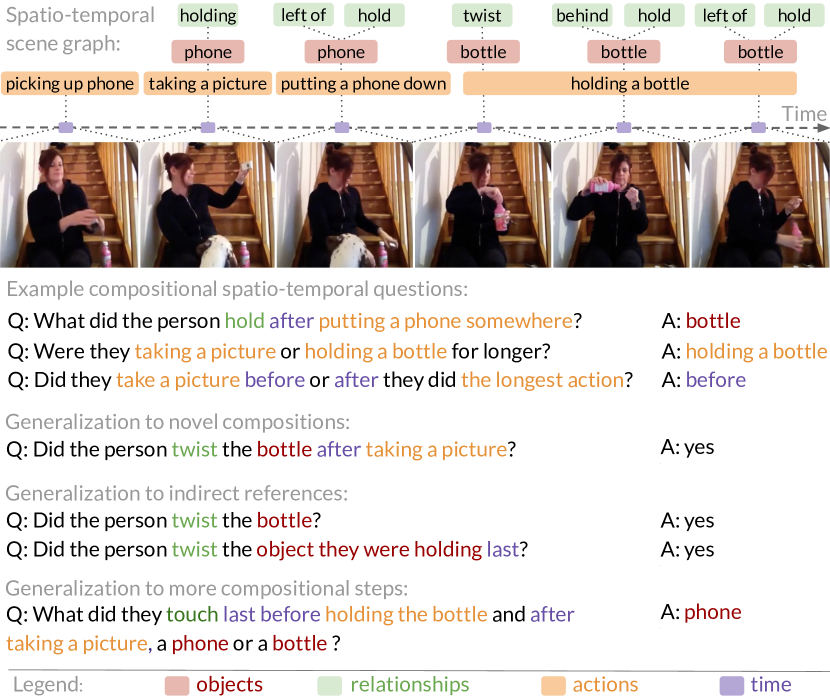
AGQA
- Publishing Team: University of Washington
- Release Year: 2021
- Download Link: https://agqa.cs.washington.edu/
- Dataset Size: Contains approximately 96,000 videos and over 150,000 questions with corresponding answers
- Description: The research team collected a large number of diverse videos from the internet, covering various real-life scenes and events, such as family activities and outdoor sports. AGQA creates questions through a combination of manual annotation and automatic generation. These questions are designed to test the model's understanding and reasoning capabilities regarding video content, including inquiries about actions, events, objects, attributes, and more, such as "What did the person in the video do before opening the door?" The questions in the AGQA dataset are highly complex and diverse, requiring models to possess strong logical reasoning and language comprehension abilities to answer accurately. It covers multiple semantic types of questions, such as causality, temporal order, and action intent, providing rich material for researching the reasoning capabilities of videoQA systems. Additionally, the dataset offers detailed annotation information, including question categories and answer types, facilitating in-depth analysis and evaluation of model performance by researchers. This contributes to advancing video understanding and question answering technologies, enabling models to better handle complex real-world video content comprehension tasks.
HowToVQA69M
- Publishing Team: ShareGPT4V Team, composed of members from the University of Science and Technology of China, Shanghai Artificial Intelligence Laboratory, and others
- Release Year: 2024
- Download Link: https://antoyang.github.io/just-ask.html
- Dataset Size: Contains 69 million video-question-answer triplets, with a total video duration of approximately 4.8 million hours.
- Description: The research team collected a large amount of video data from the internet and utilized GPT-4v's visual capabilities to annotate the videos, resulting in 40,000 annotated video clips (totaling 291 hours). Based on this, the dataset was expanded to 69 million entries using a model that automatically generates video descriptions. The questions revolve around various aspects of the video content, including actions, scenes, objects, events, and more. A notable feature of the HowToVQA69M dataset is its massive scale, providing abundant data resources for model training. The generated descriptions include rich world knowledge, object attributes, camera movements, and detailed and precise temporal descriptions of events, which help enhance the model's deep understanding of video content. Additionally, the complexity and diversity of the questions in the dataset are high, covering multiple semantic types such as causality, temporal order, and action intent, effectively advancing the reasoning capabilities of videoQA systems and enabling models to better handle complex real-world video understanding tasks. Furthermore, the dataset's detailed annotation information facilitates in-depth analysis and evaluation of model performance, providing strong support for research in multimodal understanding and generation related to videos.