The Most Comprehensive Sharing for 3D Generation Dataset: Part 2, Text-to-3D
With the rapid development of artificial intelligence and computer graphics, 3D generation technology has been widely applied in fields such as virtual reality (VR), augmented reality (AR), game development, film special effects, and robotics. In recent years, text-to-3D datasets, as a new research direction, have attracted significant attention. This article is the first in the "Most Comprehensive 3D Generation Dataset Sharing Series," where we will organize and introduce the most comprehensive core open-source 3D generation datasets for interested researchers to reference. This article will delve into the conceptual characteristics of text-to-3D datasets and share important open-source datasets for text-to-3D generation.
Overview of Text-to-3D Datasets
Text-to-3D datasets refer to datasets that generate 3D objects, scenes, or structures based on natural language text descriptions. These datasets typically consist of a large number of text descriptions of objects or scenes, with each description containing information about various features such as appearance, shape, size, color, and material. Using these text descriptions, models can generate corresponding 3D data, such as 3D models, point clouds, voxel grids, and more.
Text-to-3D datasets provide an interdisciplinary research platform that combines natural language understanding, computer vision, and computer graphics. In the process of converting text descriptions to 3D images, models not only need to understand the semantics of the text but also translate the text into actual representations in 3D space. Therefore, text-to-3D datasets not only challenge the computer's ability to understand natural language but also drive advancements in 3D image generation technology. Text-to-3D datasets have the following characteristics:
- Cross-Domain Integration: Text-to-3D datasets bridge the fields of natural language processing (NLP) and computer graphics (CG). The process of generating 3D objects requires models to understand the details in the text and accurately map these details into 3D space, involving technologies such as deep learning, image generation, and 3D modeling.
- Rich Corpus: Compared to traditional 3D datasets, text-to-3D datasets offer greater freedom in descriptions. Through natural language, researchers can flexibly describe objects or scenes, providing a richer corpus for generating 3D objects with complex structures and semantics.
- Diverse Outputs: Text-to-3D datasets are not limited to generating traditional 3D models but can also produce various types of 3D data, such as point clouds, voxel grids, depth maps, and 3D texture maps. This diversity makes the datasets widely applicable in different scenarios, including object generation, complex scene reconstruction, virtual environment creation, augmented reality, and more.
Open-Source Text-to-3D Datasets
With the advancement of 3D generation research, many universities and research institutions have released mature open-source datasets to promote the development of text-to-3D technology. Below, we have compiled important text-to-3D datasets to provide references for further understanding and application of text-to-3D technology.
ShapeNet
- Publisher: Princeton University
- Download Link: https://shapenet.org/about
- Release Date: 2015
- Size: Approximately 50GB (including multiple categories and 3D models)
- Description: ShapeNet is one of the most widely used 3D object datasets, containing over 5,000 object categories and more than 300,000 3D models, covering categories ranging from furniture and vehicles to natural objects. It not only provides a vast amount of data for 3D object recognition and generation research but also serves as an important benchmark dataset for deep learning and computer vision. The models in ShapeNet are stored in standard 3D file formats (e.g., .obj) and include rich label information, such as object categories and subcategories. This dataset has become a research benchmark in fields such as 3D generation, segmentation, recognition, and retrieval.
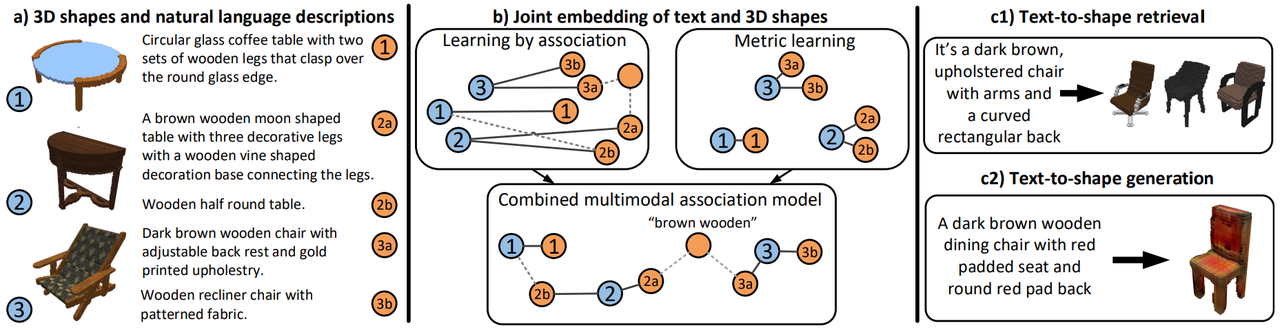
Text2Shape
- Publisher: University of California, Berkeley
- Download Link: http://text2shape.stanford.edu/
- Release Date: 2016
- Size: Approximately 2GB
- Description: Text2Shape is a dataset for generating 3D objects from text, containing natural language descriptions and corresponding 3D models. Each 3D model is accompanied by detailed text descriptions covering shape, color, material, and other information. The goal of the Text2Shape dataset is to study how to generate 3D shapes that meet the requirements based on given text descriptions. It provides a rich experimental platform for text-to-3D generation research, particularly playing a significant role in studies using deep learning to generate 3D models.
3D-COCO
- Publisher: UC Berkeley, Facebook AI Research
- Download Link: https://kalisteo.cea.fr/index.php/coco3d-object-detection-and-reconstruction/
- Release Date: 2017
- Size: Approximately 6GB (including 3D models and image description data)
- Description: 3D-COCO is a 3D dataset built upon the famous COCO dataset, primarily targeting image-based 3D object reconstruction and generation tasks. This dataset combines annotations from the COCO image dataset with 3D reconstruction information, providing associated data between images and 3D models. 3D-COCO contains a large number of object categories and provides corresponding 3D objects, scene information, and point cloud data for each image, aiming to assist researchers in tasks such as multimodal learning and image-to-3D conversion. The release of this dataset has advanced the field of 3D computer vision and has become an important resource for multimodal learning.
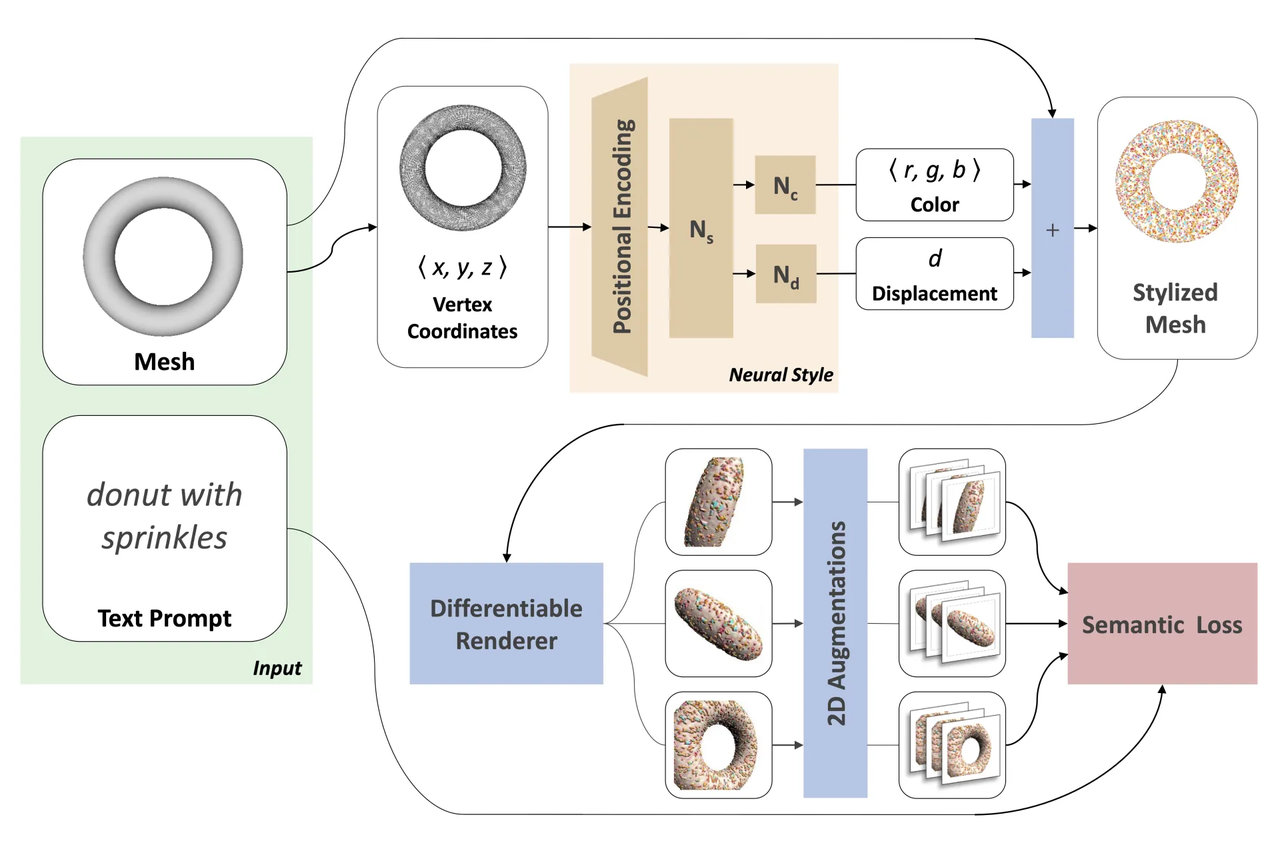
Text2Mesh
- Publisher: University of California, Berkeley
- Download Link: https://threedle.github.io/text2mesh/
- Release Date: 2019
- Size: Approximately 5GB (including text descriptions and mesh data)
- Description: Text2Mesh is a dataset designed to generate 3D mesh models from text descriptions. It contains detailed text descriptions of various objects and combines these descriptions with mesh data to construct corresponding 3D meshes. Text2Mesh is particularly suitable for tasks requiring the generation of 3D models with detailed geometric shapes, covering multiple object categories, including but not limited to furniture and vehicles. It holds significant importance for research on deriving precise 3D geometric shapes from natural language descriptions.
Text2Room
- Publisher: MIT Computer Science and Artificial Intelligence Laboratory (CSAIL)
- Download Link: https://lukashoel.github.io/text-to-room/
- Release Date: 2020
- Size: Approximately 12GB (including 3D room models and corresponding text descriptions)
- Description: Text2Room is an open-source dataset specifically designed for generating indoor scenes. It provides a large number of 3D models of room layouts, furniture, and objects, along with their text descriptions. The text descriptions in the dataset cover room structures, furniture arrangements, object placements, and more, enabling researchers to generate 3D models of rooms based on these descriptions. Text2Room is primarily applied in fields such as interior design, virtual reality, and augmented reality, driving advancements in text-based indoor 3D modeling technology.

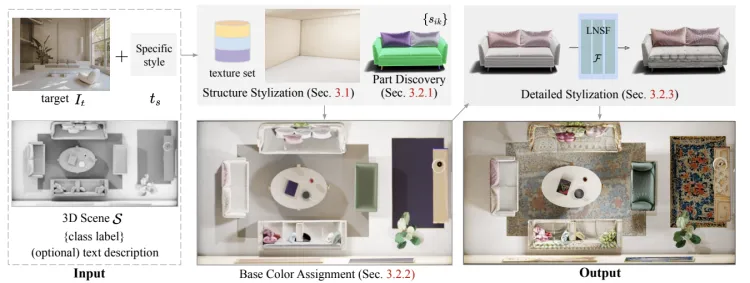
Text2Scene
- Publisher: University of Washington
- Download Link: https://openaccess.thecvf.com/content/CVPR2023/html/Hwang_Text2Scene_Text-Driven_Indoor_Scene_Stylization_With_Part-Aware_Details_CVPR_2023_paper.html
- Release Date: 2019
- Size: Approximately 10GB (including 3D scenes and text descriptions)
- Description: Text2Scene is a dataset focused on 3D scene generation, aiming to generate complex 3D scenes from natural language descriptions. These scenes include multiple objects, diverse environments, layouts, and their interactions. Each scene is accompanied by detailed text descriptions covering object categories, positions, colors, and other information. The dataset emphasizes generating multiple objects and their spatial relationships that align with scene descriptions, making it widely applicable in research areas such as automated scene generation, augmented reality, and intelligent space construction.
These datasets not only cover various types of 3D data, including objects, rooms, and geometric shapes, but also provide corresponding natural language descriptions, helping researchers explore how to translate complex textual information into real-world objects in 3D space. In addition to the open-source datasets mentioned above, Integer Smart also possesses a rich collection of text-to-3D datasets and can offer customized dataset construction services tailored to specific needs and scenarios. This commitment aims to assist academia and industry in better understanding and developing more efficient and accurate text-to-3D generation models.