The Most Comprehensive Sharing for 3D Generation Dataset: Part 1, Image-to-3D
In the previous installment of "The Most Comprehensive 3D Generation Dataset Sharing Series," we introduced and shared 3D generation datasets based on text generation, and compiled relevant important open-source datasets. In this edition of the 3D generation dataset sharing series, we will introduce and share 3D generation datasets based on image generation.
Overview of Image-to-3D Datasets
Image-to-3D datasets refer to datasets that generate corresponding 3D objects, scenes, or structures by inputting 2D images or image sequences. These datasets typically contain a large number of images along with corresponding 3D models, point clouds, voxel grids, depth maps, and other 3D data. Image-to-3D datasets utilize computer vision and graphics techniques to extract information from planar images and reconstruct the 3D structure of objects or scenes. This process usually involves recovering depth information from 2D images and generating objects or scenes in 3D space.
These datasets provide extremely important resources for research in the fields of deep learning and computer graphics. By generating 3D models from images, researchers can explore how to infer spatial layouts, depth information, and 3D shapes of objects from single or multiple images. Similar to text-to-3D datasets, image-to-3D datasets play a key role in advancing applications in computer vision, 3D reconstruction, virtual reality (VR), augmented reality (AR), and more.
Characteristics of Image-to-3D Datasets
- Integration of Computer Vision and Graphics: Image-to-3D datasets bridge the fields of computer vision and computer graphics. The process of generating 3D models requires not only the ability to understand and analyze information in 2D images but also the ability to infer the corresponding 3D spatial layout and depth information. This involves multiple technical areas such as deep learning, 3D modeling, and geometric reconstruction.
- Depth Recovery and 3D Modeling: Unlike text-to-3D datasets, image-to-3D datasets place greater emphasis on recovering depth information from 2D images. This requires models to have strong spatial reasoning capabilities, enabling them to synthesize the 3D shape and structure of objects from multiple viewpoints. With advancements in deep learning, these datasets have become a crucial foundation for training deep neural networks to solve 3D reconstruction problems.
- Multimodal Data Output: Similar to text-to-3D datasets, image-to-3D datasets often provide not only traditional 3D models but also generate various forms of 3D data such as point clouds, voxel grids, depth maps, and 3D texture maps. This diverse output allows the datasets to be widely applied in different scenarios, such as autonomous driving, robot navigation, virtual reality, and game development.
Open-Source Image-to-3D Datasets
Below are some important image-to-3D datasets, organized and introduced:
Pix3D
- Publisher: UC Berkeley
- Download Link: https://github.com/xingyuansun/pix3d
- Release Date: 2017
- Size: Approximately 30GB (including images and 3D models)
- Description: Pix3D is a dataset for generating 3D object models from single images. It contains images and corresponding 3D models from multiple object categories, aiming to advance the development of image-to-3D object generation technology. Each image is paired with a 3D model derived from multi-view 2D images. Pix3D is particularly suitable for single-image 3D reconstruction tasks and holds significant value in training deep learning models for image-to-3D conversion.
3D-R2N2
- Publisher: Princeton University
- Download Link: https://cvgl.stanford.edu/3d-r2n2/
- Release Date: 2016
- Size: Approximately 40GB (including images, 3D models, and depth information)
- Description: 3D-R2N2 is a dataset for generating 3D objects from multi-view images, primarily used to study how to recover 3D shapes of objects from multiple 2D images. The dataset contains a rich collection of 3D object models and images from different viewpoints, with each model providing depth information. 3D-R2N2 is particularly suitable for multi-view image-to-3D model generation and has driven research and applications in 3D reconstruction technology.
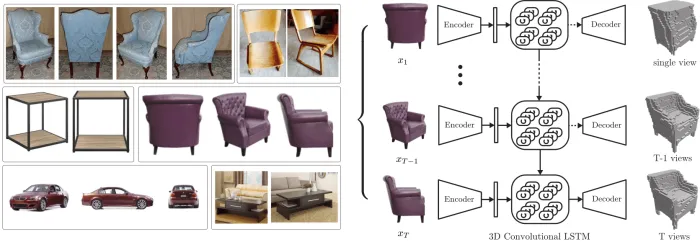
Multi-View 3D Object Detection (MV3D)
- Publisher: University of California, Berkeley
- Download Link: https://github.com/bostondiditeam/MV3D
- Release Date: 2017
- Size: Approximately 50GB (including 3D models, images, and label data)
- Description: MV3D is a dataset designed for 3D object detection, aiming to generate complete 3D object models from multi-view images. The goal of this dataset is to accurately generate and recognize 3D objects from multi-view images using deep learning techniques. The MV3D dataset not only provides rich 3D object annotation data but also includes depth information obtained from sensors such as LiDAR. It is suitable for research in fields such as autonomous driving and robot navigation.
3D-FUTURE
- Publisher: Alibaba-inc, ICT.CAS, University of Melbourne, Birkbeck College, University of London, The University of Sydney
- Download Link: https://www.3d-future.com
- Release Date: 2021
- Size: Approximately 100GB (including images, 3D models, textures, etc.)
- Description: 3D-FUTURE (3D FUrniture shape with TextURE) is a large-scale open-source dataset for researching 3D furniture model generation, texture recovery, and transfer. The dataset contains 20,240 realistic synthetic indoor images captured from over 5,000 diverse scenes. It also provides 9,992 unique industrial-grade 3D CAD furniture models, created by professional designers and accompanied by high-resolution texture information.
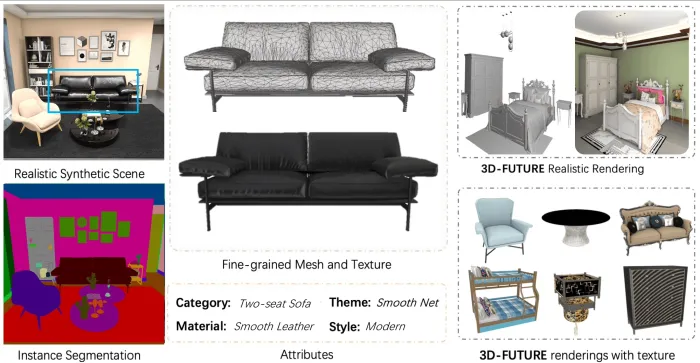
ScanNet
- Publisher: Stanford University & UC Berkeley
- Download Link: https://www.scan-net.org/
- Release Date: 2017
- Size: Approximately 800GB
- Description: ScanNet is a large-scale indoor 3D scene dataset that contains rich RGB-D images and corresponding 3D reconstruction models. The ScanNet dataset supports various tasks, including 3D scene reconstruction, semantic segmentation, object detection, and image-to-3D generation. Each scene includes extensive annotation information, such as semantic labels and depth data. Widely used in academia, ScanNet is one of the key datasets for image-to-3D generation research. Its high-quality annotations and large-scale data make it an essential reference in the fields of 3D reconstruction and scene understanding.

Matterport3D
- Publisher: Matterport, Stanford University
- Download Link: https://niessner.github.io/Matterport/
- Release Date: 2017
- Size: Approximately 200GB (including 3D models, images, and point cloud data)
- Description: Matterport3D is an indoor space reconstruction dataset that provides a large amount of 3D indoor scene data captured using Matterport cameras. The dataset includes detailed 3D models, RGB images, depth maps, and point cloud data, making it suitable for training and testing image-based 3D reconstruction and spatial perception models. Matterport3D offers valuable resources for indoor scene understanding, robot navigation, virtual reality, and other related fields.

ModelNet
- Publisher: Princeton University
- Download Link: https://modelnet.cs.princeton.edu/
- Release Date: 2015
- Size: Approximately 2GB (ModelNet10); Approximately 30GB (ModelNet40)
- Description: ModelNet is a large-scale 3D model dataset containing 3D object models from 127 object categories, with ModelNet10 including 10 categories and ModelNet40 including 40 categories. It is suitable for tasks such as 3D object recognition, classification, and retrieval. Although the primary goal of ModelNet is to provide data support for object classification, it has also been used in research for image-to-3D generation experiments. The model data is stored in standard 3D model file formats (e.g., .obj) and includes rich object category information.

Pix2Vox
- Publisher: Peking University
- Download Link: https://github.com/hzxie/Pix2Vox
- Release Date: 2019
- Size: Approximately 6GB
- Description: Pix2Vox is a dataset for image-to-3D generation, containing 2D images captured from multiple viewpoints and providing corresponding 3D models. This dataset supports 3D object generation from multi-view images and is one of the classic datasets in deep learning research. Pix2Vox stands out not only for its image-to-3D generation tasks but also for its support of multi-view 3D reconstruction, offering strong support for research in the field of image-to-3D generation.
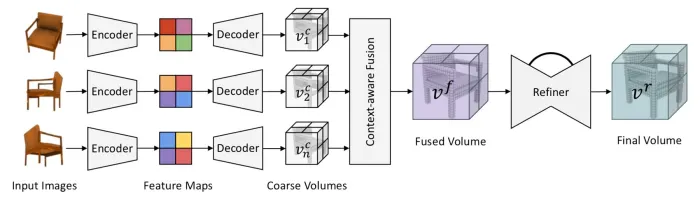
Image-to-3D datasets provide extremely important resources for the fields of computer vision and graphics. These datasets not only help researchers recover 3D information from images but also drive applications in autonomous driving, robotics, virtual reality, and other domains. In addition to the open-source datasets mentioned above, Integer Smart also possesses a rich collection of text-to-3D datasets and can provide customized dataset construction services tailored to specific needs and scenarios. Through these datasets and services, academia and industry can deeply explore complex 3D scene understanding and generation tasks, promoting the continuous advancement of 3D reconstruction technology.