Promoting the Democratization of Artificial Intelligence: The Groundbreaking Release of MAP-Neo, the First High-Quality Bilingual Open-Source Large Language Model!
Github Link: https://github.com/multimodal-art-projection/MAP-NEO
In response to the growing demands of artificial intelligence development, large language models (LLMs) are continuously evolving and demonstrating powerful capabilities in many natural language processing (NLP) tasks. However, the rapid commercialization of LLMs has resulted in the most advanced models being closed-source, with critical details such as training data, model architecture, and infrastructure specifics not publicly disclosed. For LLM researchers, these undisclosed details are crucial for model research and development. Although fully open-source LLMs are available for researchers, there remains a significant performance gap between these open-source models and commercial LLMs, especially in Chinese language processing and certain reasoning tasks, where their performance still lags far behind that of commercial models.
Given the lack of sufficiently open and transparent advanced LLMs in the research community, the Multimodal Art Projection (M-A-P) team has introduced MAP-Neo, a fully open-source large language model. MAP-Neo publicly releases its cleaned pre-training dataset, data cleaning details, all checkpoints, and evaluation code. M-A-P hopes that MAP-Neo will strengthen and consolidate the open research community and inspire a new wave of innovation.
As a member of the M-A-P team, Abaka AI has been fully involved in the construction of MAP-Neo. High-quality training data is essential for achieving excellent model performance. The outstanding performance of MAP-Neo stems not only from its large-scale training data but also from its rigorous data cleaning and processing pipeline. Additionally, the attempt to build a bilingual large language model by incorporating Chinese datasets has introduced new challenges in data cleaning and filtering. Alongside the open-source dataset, the M-A-P team has also publicly released the Matrix dataset and all code used to produce it.
1. Introduction to MAP-Neo
1.1 Model Overview
In the field of large AI models, tech giants have established a framework of data colonialism through algorithms, monopolizing and manipulating data. The concept of data colonialism suggests that the immense data power of U.S.-led tech giants, facilitated by large model algorithms, manipulates user behavior and judgment, continuously tracks and records human activities, and secures industry monopolies while reaping substantial profits. In response to this reality, the concept of democratizing artificial intelligence has emerged. Advocates believe that promoting equitable access to AI technology across all institutions can advance the democratization of AI resources, thereby reducing the risks of data colonialism. Within AI technology, large language models dominate. Increasing the availability of open-source LLMs and fostering competition with closed-source commercial models can simultaneously address the shortage of open AI resources and concerns over data security and privacy.
Moreover, most so-called open-source LLMs do not disclose critical aspects of their development process, such as data sources, pre-training code, and data processing pipelines, which are the most costly components of building LLMs. Existing open-source LLMs fall short of providing researchers with a reliable resource for use and reference.
Additionally, most existing LLMs are trained from scratch on English corpora. Enabling non-English language communities to benefit from open-source models and promoting data and AI democratization in non-English regions remains an area requiring further exploration.
To address these challenges and achieve transparency in LLM training, the Multimodal Art Projection (M-A-P) research team has released MAP-Neo, a fully open-source large language model. MAP-Neo includes final and intermediate checkpoints, a self-trained tokenizer, a pre-training corpus, and an efficient, stable pre-training codebase. The MAP-Neo model is trained from scratch on 4.5 trillion Chinese and English tokens, achieving performance comparable to LLaMA2-7B. In challenging LLM tasks such as reasoning, mathematics, and coding, MAP-Neo outperforms models of similar training data scales, demonstrating performance on par with proprietary models.
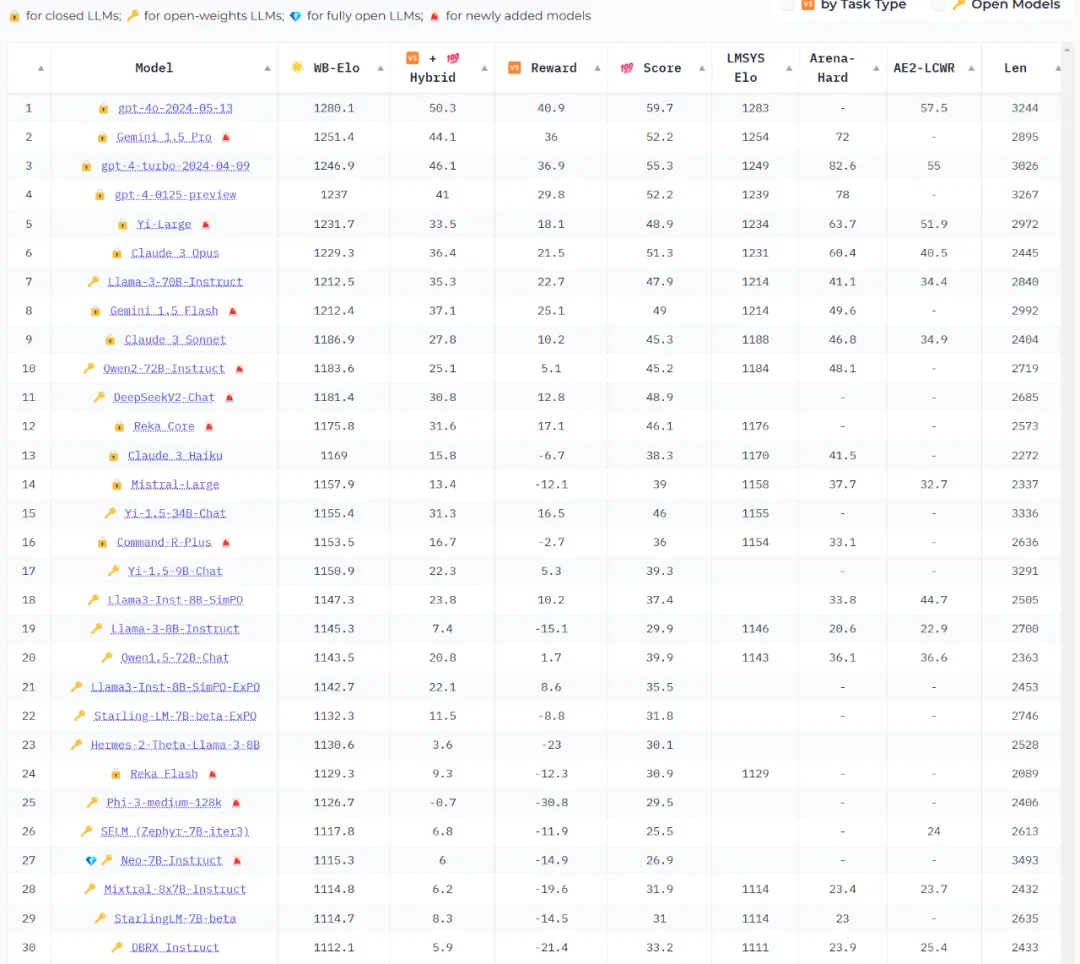
MAP-Neo 7B is fully open-source, with the team publicly releasing data including the base model and a series of intermediate checkpoints, aiming to support broader and more diverse research in both academia and industry.
1.2 Performance of MAP-Neo 7B
In terms of performance, MAP-Neo 7B demonstrates exceptional capabilities across a wide range of benchmarks. Compared to models of similar training scales, MAP-Neo 7B's performance aligns with or even surpasses that of leading closed-source commercial large language models.
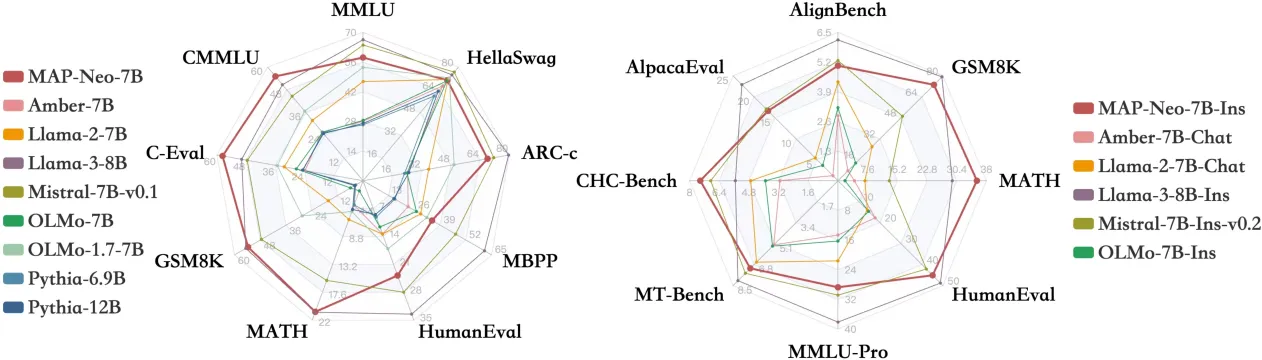
1.3 A Milestone for Fully Open-Source Language Models
The release of MAP-Neo marks a milestone in large language model (LLM) research, signifying that fully open-source and transparent LLMs now possess advanced capabilities and performance comparable to closed-source commercial models. The contribution of the M-A-P team goes beyond building an unprecedented foundational model shared with researchers across the industry; it also provides a fully transparent, step-by-step guide for constructing LLMs from scratch. The M-A-P team welcomes enterprises in need of Chinese LLMs but constrained by limited access to existing models to use or reference MAP-Neo, fostering a more vibrant and diverse Chinese LLM enterprise community. This initiative also serves as a valuable reference for global LLM research, particularly in non-English-speaking regions.
2. Model Advantages
Compared to previous LLMs, MAP-Neo achieves an excellent balance between model performance and transparency. As the first open-source, transparent bilingual LLM, MAP-Neo breaks the current paradigm where open-source LLMs significantly underperform compared to closed-source commercial models. It also provides a fully transparent pipeline for building LLMs.
2.1 "Thoroughly" Open-Source Model
Unlike previous closed-source commercial models and open-source models, MAP-Neo is more thoroughly open-source, disclosing all critical processes from raw data collection and cleaning to the pre-training codebase. This comprehensive openness significantly reduces the cost of future deployment and customization of LLMs, especially for Chinese LLMs.
The M-A-P team has publicly released and detailed the following components and processes of MAP-Neo:
- Data Organization and Processing: The team released the pre-training corpus, known as the Matrix Data Pile, as well as training data for supervised fine-tuning and alignment training. They further organized Chinese and English training data, along with data cleaning code and details, including a stable OCR system, a data recall mechanism in DeepSeek-Math, integration of existing open-source data processing pipelines, and distributed data processing support based on Spark2.
- Model Training Architecture: The team publicly released the code and details of the modeling architecture, including the tokenizer, base model, instruction-tuned model, and RLHFed model training code. Additionally, they resolved certain issues with the Megatron-LM framework, enhancing its support for more robust and efficient distributed LLM training.
- Model Checkpoints: The team released the final model on HuggingFace, along with intermediate checkpoints.
- Infrastructure: The team detailed the infrastructure for stable training in the model report.
- Inference and Evaluation: The team provided complete code for inference optimization and comprehensive evaluation.
- Analysis and Lessons: The report includes numerous technical insights and tips, such as optimization techniques for different stages of pre-training, and offers rigorous analysis and ablation studies to provide insights into LLM construction.
2.2 Large-Scale Training Data
A well-structured, high-quality corpus is key to training high-performance LLMs. Due to gaps in dataset size and quality, the development of fully open-source LLMs has lagged far behind closed-source commercial models. To address the urgent need for diverse and transparent datasets in language modeling, the M-A-P team introduced Matrix, a bilingual pre-training corpus containing 4.5 trillion tokens. Matrix is set to become the largest fully transparent training corpus for LLMs. Specifically, Matrix details six processes of data collection and processing and includes a high-performance toolkit. Its construction combines the team's experience and logical design in retrieving, filtering, and performing high-quality data cleaning across various practical scenarios.
While ensuring the scale of training data, MAP-Neo-7B also strictly controls the quantity of training data to guarantee model quality and efficiency. Furthermore, the M-A-P team has fully transparently disclosed the data processing pipeline.
2.3 Bilingual Chinese-English Corpus
Facing the challenges of underdeveloped high-quality Chinese datasets and a shortage of high-quality Chinese corpora, the construction of MAP-Neo-7B based on Chinese and English training data holds significant value for improving Chinese datasets. The M-A-P team not only enriched the accumulation of high-quality Chinese datasets but also publicly shared the entire process of obtaining high-quality Chinese training data through data filtering and cleaning. This provides an effective reference and methodology for future expansions of Chinese datasets.
2.4 Construction of High-Quality Training Datasets
Obtaining high-quality data is crucial for ensuring model performance. By utilizing high-quality data, MAP-Neo demonstrates significantly better performance in mathematics, coding, and complex reasoning tasks compared to previous open-source low-quality LLMs (such as Amber and Pythia). The team publicly released the entire pipeline for filtering and cleaning both English and Chinese data, sharing insights on how to effectively obtain high-quality training data that meets the needs of efficient model training.
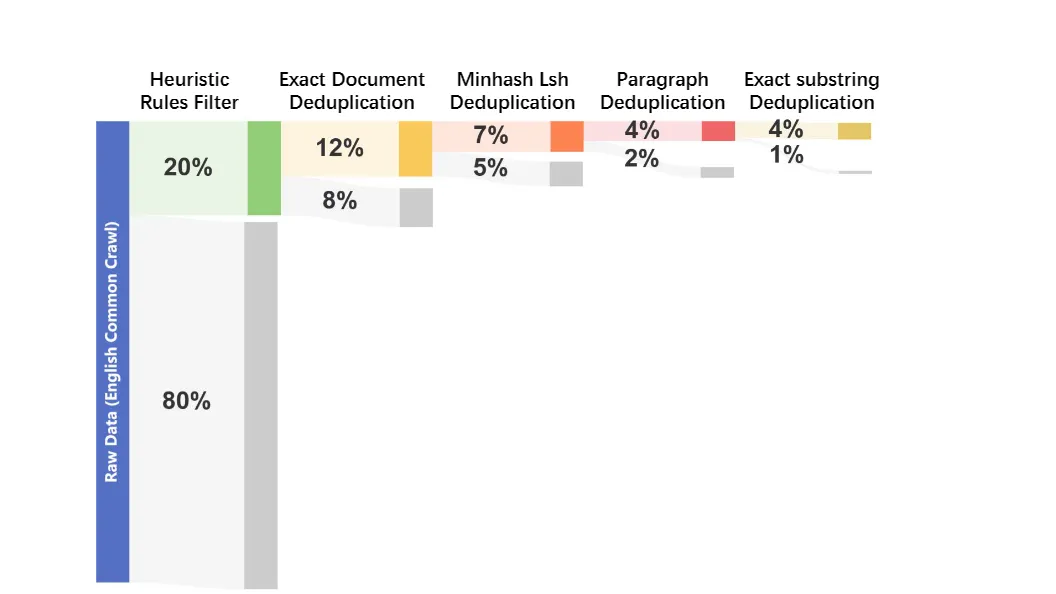
- Open Dataset Reprocessing Pipeline
Based on previously released open-source pre-training corpora, the M-A-P team designed a more refined pipeline to reprocess existing data, generating the English subset of the Matrix data mixture and further improving data quality. The team has publicly disclosed the data sources and the steps for data filtering and deduplication.

It is worth noting that by using reprocessed, higher-quality data for continuous pre-training, the performance of existing large language models can also be significantly and rapidly improved.
- Data Filtering
The team employed heuristic rules for text filtering to remove low-quality corpora from open-source datasets. Heuristic rules can effectively identify and eliminate low-quality data, preventing it from affecting model performance. Since the team used composite data from multiple sources, they designed specialized cleaning methods tailored to each source to maintain consistent data quality.
Specifically, the team annotated the quality of all texts using the RedPajama-Data-v2 dataset and combined heuristic filtering rules with quality annotations to refine data quality assessment. Additionally, the team performed random sampling on the datasets to determine thresholds corresponding to different rules. For datasets lacking high-quality annotations, the team customized rules and thresholds in RedPajama-Data-v2 based on their unique characteristics to achieve quality alignment. The filtering process includes:
- Data Deduplication
Duplicate text can degrade model performance. By removing duplicates, the rate of memorization can be significantly reduced, making model training more efficient. Therefore, deduplication is a critical step in corpus processing. Duplicate data can be categorized into exact duplicates and near duplicates.
For exact duplicates, the team applied exact document deduplication. For near duplicates, the team used the Minhash text deduplication method. To address instances of text replication, the team employed both paragraph deduplication and exact substring deduplication to remove as many duplicates as possible.
For the Chinese corpus, the M-A-P team designed a pipeline to scrape and process web data from scratch, presenting it in the form of Chinese data. For the construction of Chinese corpora, the Neo dataset and the team's publicly shared pipeline can serve as a reference guide for subsequent research. The team used the corpus formed by this pipeline as the Chinese subset of Matrix, with 80.6% of the data coming from Chinese web scraping and the rest from multiple open-source datasets.
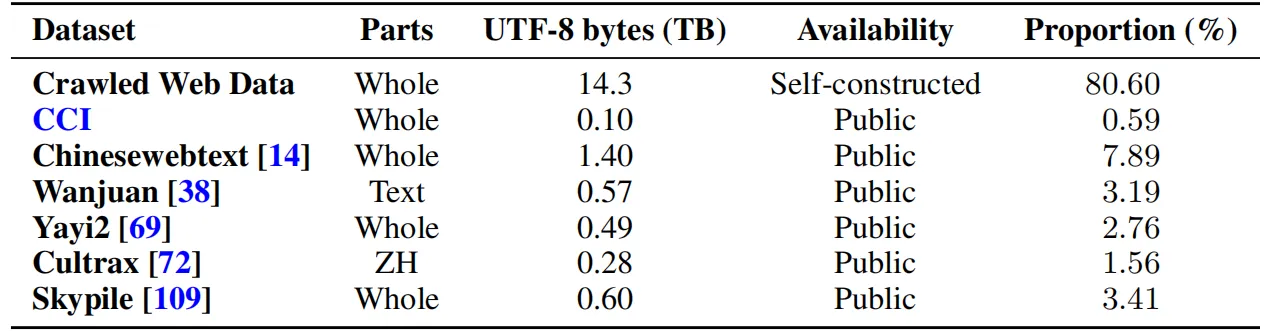
- Data Filtering
Given the unique characteristics of Chinese data, the team adopted filtering rules different from those used for English datasets. Considering the significant proportion of HTML-converted data in Chinese datasets, the focus of filtering was on eliminating HTML-related artifacts and correcting text inconsistencies. Additionally, due to the substantial differences in linguistic structure between Chinese and English, the team conducted targeted sampling of documents in the Chinese dataset and re-evaluated and adjusted the thresholds and details of filtering rules based on the sampled content. This ensured that the data filtering methods were suitable for the unique linguistic features of Chinese text. For example, the team improved filtering rules for Chinese "characters" and "words" and adjusted the tokenization methods accordingly.
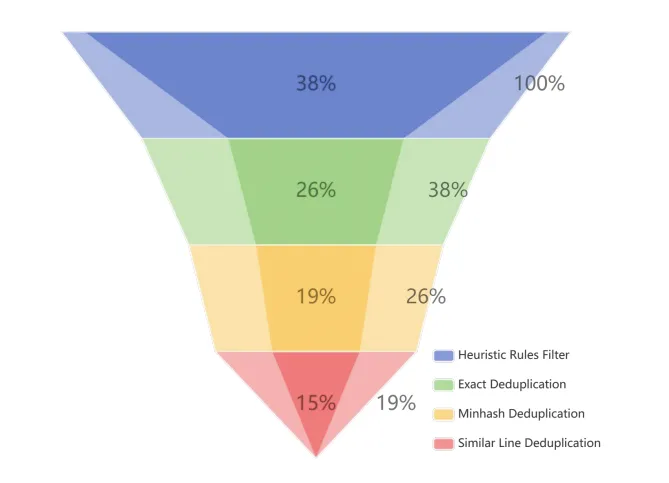
- Data Deduplication
Deduplication methods for Chinese data include exact deduplication, MinHash deduplication (a minimum independent permutation locality-sensitive hashing scheme), and similar line deduplication. Given the difficulty of deploying Spark in Chinese environments, the team developed a new approach for deduplication in Chinese contexts. For exact deduplication, to save memory, the team used a Bloom filter with a false positive rate set to 0.001. Since web scraping often results in multiple captures of the same content within a single document, the team avoided exact substring deduplication. Additionally, extracting main text from HTML often leads to the loss of individual words. These two issues violate the assumption that "except for mutual references or citations from the same text, identical content rarely appears in the same form within documents." Therefore, performing exact substring deduplication would result in retaining extra words, significantly reducing text readability. To address this contradiction, the team proposed the Similar Line Deduplication method.
Similar Line Deduplication Method: To address the issue of repeated content within texts, a direct approach is to use specific delimiters to divide the text into lines and then compare the similarity between lines. If lines are similar, subsequent lines are deleted. The M-A-P team used edit distance to determine whether two lines were similar.
Compared to web-scraped data, document data typically has a more structured format, focused themes, and more consistent expressions. However, different documents have varying layout standards or exist as scanned images of varying quality, making dataset construction through document conversion equally challenging. To address this, the M-A-P team designed a specialized pipeline to extract high-quality text from documents. The document conversion pipeline focuses on two core issues: 1. Analyzing layout information to identify different layout elements, and 2. Recognizing the relationships between these layout components.
The M-A-P team investigated all existing open-source document conversion solutions, comprehensively analyzing the strengths and weaknesses of different processing pipelines. They proposed a decoupled framework that integrates the advantages of current models, such as using PaddleOCR to enhance language support and PP-StructureV2 for efficient layout parsing. The document conversion framework of MAP-Neo consists of four parts: layout detection, element recognition, sorting, and post-processing. The decoupling of each module enhances the interpretability of the process, while the team further simplified the optimization, addition, and replacement processes.
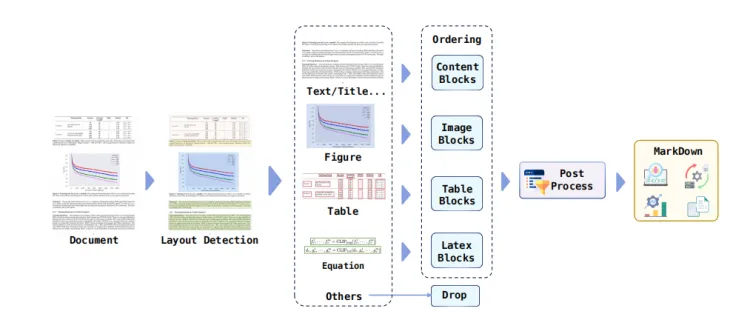
- Layout Detection
The text is divided into multiple sections, including formulas, text, headers, and footers. The layout detection pipeline uses a lightweight object detection model from PP-StructureV2, enhanced with the FGD algorithm to improve model performance and optimize feature extraction, achieving more accurate layout detection.
- Element Recognition
Different models are used for recognizing different elements. For formula recognition, the team employs the TrOCR model trained by Pix2Text, which can identify formulas embedded in paragraphs and unconventional formulas, effectively handling most formula recognition scenarios. Text recognition uses the PP-OCRv4 model, which is compatible with multiple computing devices and offers strong recognition capabilities. Graphics are saved as images during recognition and passed to the merging stage. Table reconstruction is implemented using SLANet and represented in HTML format. Headers, footers, and page numbers are discarded as irrelevant data and do not proceed to the post-processing and reconstruction stages.
- Sorting
Properly handling the relationships between different modules is crucial during document conversion. High-quality conversion data requires addressing complex scenarios such as multi-column or cross-page text environments. In the sorting stage, MAP-Neo uses the LayoutLMv3 model for row and column detection and sorts different regions based on specific rules, improving task accuracy and significantly optimizing readability.
- Post-Processing
Text extracted by OCR often cannot be used directly and requires additional processing. Post-processing includes scenarios such as identifying and reconnecting fragmented sentences across lines or pages, merging hyphenated English words into complete words, and supplementing or correcting missing elements and incorrect symbols in mathematical formulas.
By combining the above models and processing pipelines, the quality and consistency of document text data are significantly improved, and the readability and usability of the extracted content are optimized. MAP-Neo uses the efficient AI inference deployment tool FastDeploy6 as the codebase to implement these strategies, leveraging multi-threading to optimize inference speed and computational costs.
MAP-Neo also includes a high-quality supplementary dataset suitable for various scenarios, enhancing data robustness. The iterative pipeline process consists of the following stages:
- Seed Dataset Collection: Collect high-quality seed datasets in relevant fields such as mathematics, coding, or Wikipedia-based content.
- Domain Definition and Sampling: Define domains as data entries sharing the same base URL in the seed dataset and extract samples from each domain as positive samples to enhance format diversity. An equal amount of data is obtained from general scraping as negative samples.
- Model Training: Use the FastText model for binary classification to determine the relevance of data to the specified domain. The model is quantized to improve efficiency with limited content, reducing the data size to about 10% of the original.
- Data Credibility Assessment: Use the FastText model to assess the credibility of publicly scraped data and determine if it is positive data. Retain data sorted from highest to lowest confidence, simplifying the confidence ranking process by sampling subsets and balancing data exclusion and retention needs to determine a feasible threshold.
- Data Evaluation: Use ChatGPT 3.5 to evaluate retained data and determine field specificity using URLs. This stage aims to reduce false positives while maintaining necessary data recall.
- Data Recall and Annotation: Data with a revisit rate exceeding 10% is categorized as a special domain, and subsets of this domain are annotated using ChatGPT 3.5 via URLs.
- Model Refinement and Iteration: Integrate previously unconfirmed benign data into positive samples to enrich the FastText model training base and initiate new iteration cycles during the training phase.
3. Development Team: Multimodal Art Projection (M-A-P)
Multimodal Art Projection (M-A-P) is an open-source research community established in July 2022. Its members are dedicated to researching artificial intelligence-generated content (AIGC) topics, including text, audio, and visual modalities, and developing large language model training, data collection, and interesting applications. The community's research focuses on machine learning for multimodal arts, including but not limited to music. The goal is to create a space where researchers from diverse backgrounds can collaborate and share their expertise to advance the understanding of AIGC.
The M-A-P team unanimously believes that, given the significant resources required to develop a high-quality large language model, open-source and transparent LLMs are crucial for democratizing LLMs and furthering academic research. Although MAP-Neo already demonstrates excellent performance compared to current open-source LLMs, with capabilities in mathematics, coding, and Chinese knowledge testing on par with or exceeding commercial models, its overall performance still lags behind leading closed-source commercial models of similar scale. M-A-P calls for more professional teams to join the development of open-source LLMs to further promote their democratization.
As a member of the M-A-P team, Abaka AI participated in the construction of the MAP-Neo model. Leveraging extensive data processing experience, Abaka AI provided professional solutions for building high-quality training datasets. Its intelligent data engineering platform, MooreData Platform, and highly specialized, standardized data processing services contributed to the development of training data. Abaka AI is proud to be a part of the democratization of LLMs and the construction of Chinese LLMs. It remains committed to building higher-quality LLMs, continuing efforts in open-source model development, and providing professional support for data processing and model construction, advancing open-source LLMs and cutting-edge research.